LZ4 压缩算法文件格式理解
五一期间研究了一下 LZ4 压缩算法相关的一些东西。做一个备忘,本篇文章并不覆盖官方文档的全部内容,主要介绍难以 LZ4 文件格式中理解的内容。
LZ4 是一种追求极致压缩与解压速度的压缩算法。由 Yann Collet 开发,Yann Collet 应该是一名非常出色的压缩算法专家,还著有另外一个近年大热的 zstd 压缩算法。zstd 现在属于 Facebook 的开源项目。
在研究 LZ4 压缩文件格式过程中,我在网上找了很多关于 LZ4 的介绍,讲解都不够透彻,至少对我而言不够全面,仔细看过也不能完全理解 LZ4 文件格式编码的全部奥义 。通过使用 LZ4 工具进行文件生成,以及对比 LZ4 源码,最终完全弄懂了 LZ4 的文件编码方式。
术语
为了行文方便,统一对英文术语做如下翻译:
-
Magic Number:文件标识符(魔幻数)
-
F. Descriptor:文件描述符
-
Block:数据块
-
EndMark:结束符
-
C. Checksum:校验字
文件结构
LZ4 的整体文件结构是比较好理解的,可以参见 https://github.com/lz4/lz4/blob/dev/doc/lz4_Frame_format.md
文件结构如下:
| 文件标识符 | 文件描述符 | 数据块 | …… | 结束符 | 校验字 | |
|---|---|---|---|---|---|---|
| 字节数 | 4 | 3 - 15 | 0 - n | 4 | 0 / 4 |
文件标识符固定为0x184D2204,小端模式文件描述符字节长度 3 - 15,包含有如下信息:- LZ4 协议版本号
- 数据块独立性设置标志
- 数据块是否包含校验字
- 被压缩文件的大小(可配置是否携带)
- 数据块最大长度
- 字典 ID 等等
数据块恢复压缩文件的重要信息全部包含在数据块中(重点理解,后文详细展开)结束符标识数据块结束校验字文件完整性校验
LZ4 压缩文件的结构如前文所述,是比较符合逻辑的定义,其中有些字段使用了动态长度的方式,主要是为了节省一些空间,不过由于除数据块之外的字段总共最大也只有 20 多个字节,可以压缩的空间不大。
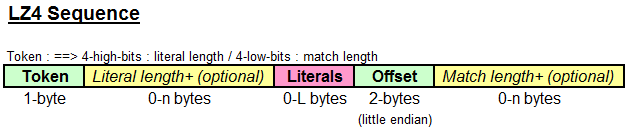
数据块结构 (LZ4 Data Block Format)
数据块的编码结构是 LZ4 的核心,其压缩的思想也主要体现在这里面。官方文档仅对编码结构做了一般性描述,对于 offset 字段的介绍十分云里雾里。下面按照我个人的理解进行一下阐述:
-
数据块可以由多个 Token 组成
-
Token 头部可以分为两个 4 位的区域,高四位表示字面量长度(t1),低四位表示数据匹配长度(t2)。
-
由于 t1、t2 只能表示 16 个信息,对于更长的信息就无可奈何了,原协议提供了一个比较巧妙的办法(编码效率并不高)。当 t1 或 t2 为 15 时,e1 和 e2 区域启用,e1 和 e2 可以包含多个字节,直至其不为 0xFF(例如:FF E8)
-
字面量长度为:t1 + e1[0] + ... + e1[n]
-
数据匹配长度为:t2 + e2[0] + ... + e2[n] + 4 (最少4个字节)
-
offset 表示当前偏移位置(curPos)与匹配区域起始位置(matchPos)的偏移
- matchPos = curPos - offset
- 初始时 curPos 为0,每解压一个字节增一
- matchPos 大于 0,匹配已解压区域
- matchPos 小于 0,匹配字典,从字典末端向前偏移(非常重要)
-
由于 offset 定义为 2 个字节,故此字典大小不超过 64KB